Build scalable, repeatable models with Red Hat AI modular building blocks
In this blog, we will learn how to build scalable, repeatable models with Red Hat AI modular building blocks.
Moving generative AI (GenAI) from proof-of-concept to full-scale enterprise adoption is rarely straightforward. Each industry—whether healthcare, financial services, manufacturing, or retail—comes with its own terminology, data structures, regulatory requirements, and risk profiles. These realities make generic AI workflows insufficient. Mission-critical deployments require purpose-built approaches that deliver control, accuracy, and operational rigor.
Red Hat AI addresses this challenge by delivering an advanced model customization experience inspired by InstructLab and extended for enterprise needs. Built on a modular architecture powered by Red Hat, developed Python libraries, this approach retains the openness and extensibility that made InstructLab successful, while adding the flexibility, scalability, and reliability required for production environments.
This evolution allows AI engineers and ML practitioners to tailor training techniques, orchestrate complex pipelines, and scale model customization efficiently—without sacrificing the ability to adapt as new methods and research emerge. The outcome is a robust, enterprise-ready path to model customization that balances speed with governance and precision.
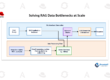
Core building blocks for enterprise model customization
At the center of this architecture are three foundational components designed to support model fine-tuning and integration with retrieval-augmented generation (RAG):
- Docling for data processing
- SDG hub for synthetic data generation
- Training hub for fine-tuning and continual learning
Each component is modular and can be used independently or combined into a complete end-to-end workflow. Red Hat also delivers supported notebooks and AI/data science pipelines that demonstrate not only how these technologies work, but how to adapt them to specific data sources, models, and operational requirements—while ensuring reliable execution at scale.
Docling: Enterprise-grade document intelligence
Docling is Red Hat’s supported solution for document processing and structuring. As a leading open source project in document intelligence, it enables organizations to confidently preprocess and organize enterprise content across formats such as PDF, HTML, Markdown, and Microsoft Office files.
Docling is designed for more than local experimentation. Through tight integration with Kubeflow Pipelines, it supports large-scale document processing on OpenShift AI, enabling use cases such as RAG, information extraction, and compliance-driven workflows.
SDG hub: High-quality synthetic data pipelines
SDG hub provides a modular framework for designing and orchestrating high-quality synthetic data pipelines used in model training and adaptation. It includes a growing library of validated, production-ready pipelines that accelerate both data generation and fine-tuning workflows.
With the SDG hub, teams can:
- Use validated pipelines immediately for training workflows
- Combine LLM-driven components with traditional data-processing steps
- Orchestrate everything from simple transformations to complex, multi-stage pipelines with minimal code
- Extend existing pipelines by building and plugging in custom components
Designed with transparency and reusability in mind, SDG hub ensures synthetic data pipelines are auditable, consistent, and suitable for enterprise production. As the library continues to expand, teams can move faster without compromising data quality or governance.
Training hub: Unified access to advanced training methods
The training hub provides a consistent abstraction layer for accessing state-of-the-art training algorithms. It exposes a stable API that remains unchanged even as algorithms mature and are adopted by upstream communities. This enables early access to innovation without disrupting existing workflows.
With the Red Hat AI 3 release, the training hub supports multiple advanced training techniques, including:
- Supervised fine-tuning (SFT) from `instructlab.training.`
- Orthogonal subspace learning for large language models, enabling continual learning while mitigating catastrophic forgetting
- Full compatibility with LAB’s multiphase training pipelines
- Support for modern open source models such as GPT-OSS for both fine-tuning and continual learning
These algorithms integrate with the Kubeflow SDK and Kubeflow Trainer, allowing distributed, production-grade training runs on Red Hat OpenShift AI.
From experimentation to enterprise deployment
To simplify adoption, Red Hat AI delivers guided workflows that take users through the complete lifecycle—from document processing with Docling, to synthetic data creation with SDG hub, to model fine-tuning with the training hub.
While these examples are developed in the open source community, enterprises can run them with full support on OpenShift AI using Red Hat’s validated builds.
From a user experience standpoint, data scientists begin by experimenting in workbenches using notebooks and scripts. Once results meet expectations, the same workflows can be promoted to enterprise-scale execution. Distributed training is handled by Kubeflow Trainer, while multi-step workflows are orchestrated using Kubeflow Pipelines—reusing the same pipeline components to seamlessly scale from prototype to production.
Customizable user experience with Red Hat AI
Red Hat AI enables first-class model customization by implementing each workflow step as a discrete, reusable component within Kubeflow Pipelines. This design simplifies complex customization efforts while delivering flexibility, extensibility, and long-term maintainability across teams and use cases.
Conclusion
Most foundation models lack awareness of the private data that truly defines an enterprise—internal documentation, business processes, and domain-specific knowledge. Fine-tuning bridges this gap, transforming general-purpose models into assets that deliver accurate, relevant, and business-aligned outcomes.
Rather than oversimplifying the challenge, Red Hat AI provides enterprise-ready building blocks that support both rapid experimentation and dependable production deployment. Your teams contribute the expertise, and Red Hat delivers the platform that enables models to evolve intelligently, scale efficiently, and operate reliably.
By streamlining the journey from data preparation with Docling, through synthetic data generation with SDG hub, to advanced training techniques such as continual learning with the training hub—and scaling everything with Kubeflow—Red Hat AI offers a governed, accelerated path to high-impact AI solutions.
The result is a practical way to turn proprietary data into differentiated, high-value AI models that create lasting competitive advantage.