

Solving RAG Data Bottlenecks at Scale
In this blog, we will learn how to solve RAG data bottlenecks at scale.
Enterprise teams building generative AI applications—especially retrieval-augmented generation (RAG)—often run into a major challenge: the “data bottleneck.” Traditional document processing tools simply aren’t built to efficiently handle thousands of complex, unstructured files.
A more effective approach is to adopt a unified data infrastructure that combines high-speed processing with accurate document understanding. By leveraging tools like Ray Data for scalable streaming and Docling for precise parsing, organizations can rapidly transform raw documents into structured, usable data. When deployed on platforms such as Red Hat OpenShift AI or Anyscale, this approach significantly accelerates AI development—reducing processing time from days to hours while improving reliability and trust.
Understanding the RAG Data Challenge
While demos often make generative AI seem straightforward, real-world implementation tells a different story. Data preparation is typically the most time-consuming phase. For example, processing thousands of legacy PDFs—many containing tables, images, and inconsistent formatting—can quickly overwhelm traditional pipelines.
RAG systems rely on structured workflows where documents are parsed, segmented, embedded, and stored in vector databases. During inference, relevant data is retrieved and passed to large language models (LLMs) to generate accurate, context-aware responses. However, legacy systems struggle to manage the combination of CPU-intensive parsing and GPU-intensive embedding tasks efficiently.
To scale effectively, organizations need an architecture that unifies these workloads into a single pipeline.
Scaling Data Processing with Ray Data and Docling
Ray Data is purpose-built for machine learning and AI workloads. Its streaming execution model allows data to flow continuously across CPU and GPU resources, maximizing efficiency while maintaining stable memory usage. Being Python-native, it avoids unnecessary data conversions and accelerates development cycles.
On the other hand, Docling focuses on extracting meaningful structure from complex documents. It excels at interpreting layouts, tables, and formatting—ensuring that downstream AI systems receive accurate and context-rich inputs.
When combined, these tools enable distributed document processing at scale. Ray partitions datasets into smaller chunks and distributes them across worker nodes. Each node processes its assigned data independently, reading directly from storage and writing results back without overloading a central controller. This design ensures high throughput and eliminates bottlenecks.
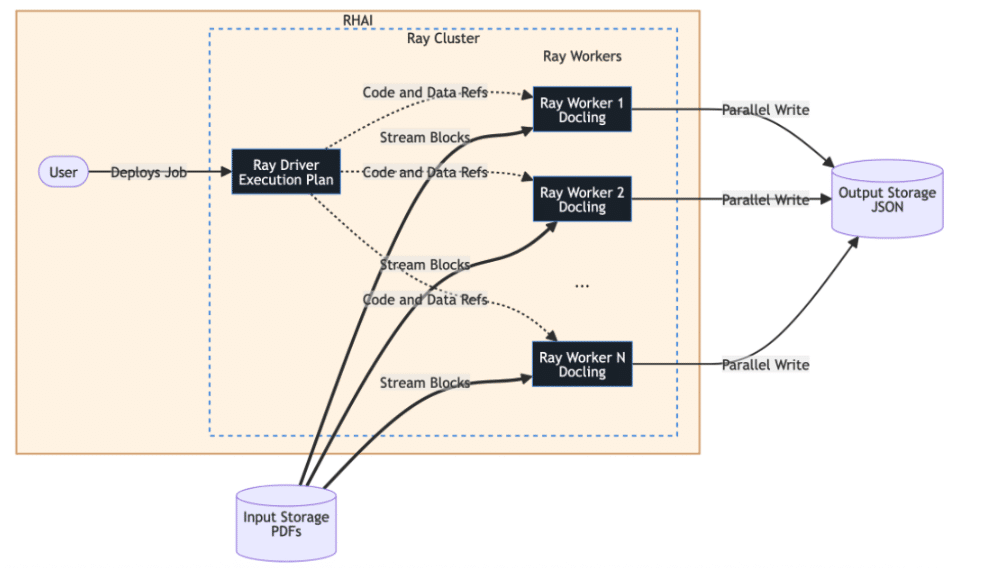
Additionally, the system can simultaneously utilize CPUs for parsing and GPUs for embedding, making optimal use of available resources.
Enterprise-Grade Operations with OpenShift AI
Red Hat OpenShift AI provides a robust foundation for running these workloads in production. Using Kubernetes-native orchestration, it enables the reliable deployment and scaling of distributed systems like Ray.
With built-in capabilities for autoscaling, fault tolerance, and recovery, the platform can dynamically adjust to workload demands—whether processing tens or hundreds of nodes. This allows organizations to handle large-scale data ingestion without manual intervention.
A typical workflow looks like this:
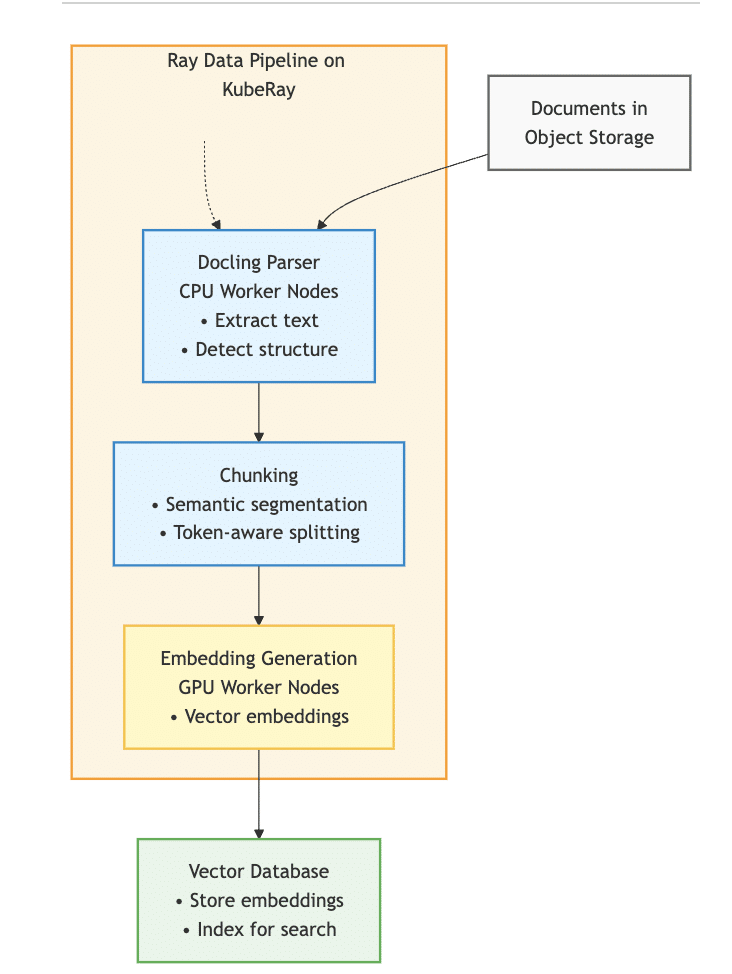
- Documents are stored in object storage systems.
- Ray pipelines distribute the workload across compute nodes.
- Docling parses and structures the data.
- Embeddings are generated using GPUs.
- Results are stored in vector databases such as Milvus.
- Applications retrieve relevant context and feed it into LLMs for accurate responses.
By running everything within a unified Kubernetes environment, organizations can meet compliance requirements, reduce operational complexity, and streamline both data preparation and model deployment.
Looking Ahead: From RAG to Agentic AI
The next evolution of enterprise AI goes beyond simple retrieval systems toward more advanced, agent-driven workflows. These systems rely on multi-step reasoning, combining RAG with techniques like retrieval-augmented fine-tuning (RAFT) to improve accuracy and reduce irrelevant outputs.
As AI agents become more autonomous, the quality of underlying data pipelines becomes even more critical. Well-structured, high-quality data enables agents to perform complex tasks reliably and safely.
Organizations that invest in scalable, unified infrastructures today will be better positioned to support these advanced AI capabilities. Efficient data pipelines will serve as the backbone for future innovations, enabling systems that can reason, adapt, and act with greater precision.
Conclusion
Combining platforms like Red Hat OpenShift AI with technologies from Anyscale provides a powerful solution for overcoming data processing challenges in generative AI. By leveraging tools such as Ray Data and Docling, enterprises can turn complex, unstructured documents into meaningful insights at scale.
This shift allows teams to move beyond data bottlenecks and focus on building impactful AI applications that solve real-world problems.





