Cost-Efficient Edge Platforms Using OpenShift and Portworx
In this blog, we will learn how OpenShift and Portworx enable cost-efficient edge platforms.
Meeting the growing demand for edge deployments
The push to run applications closer to where data is generated has never been stronger. From retail outlets and remote branches to factories and industrial facilities, organizations increasingly need to process, analyze, and store data directly at the edge. While edge environments unlock faster insights and localized decision-making, they also introduce unique challenges—limited physical space, constrained hardware budgets, and the need for resilient operations across many distributed locations.
Designing applications for the edge therefore requires balancing site-specific requirements with the broader cost and operational complexity of deploying, managing, and maintaining platforms at scale.
A new approach to cost-efficient edge resilience
Red Hat OpenShift continues to evolve to address these edge-specific demands. With the introduction of the two-node OpenShift with arbiter topology, Red Hat—together with ecosystem partners such as Portworx—is delivering a resilient, highly available architecture optimized for edge use cases, without the cost burden of traditional three-node clusters.
This design directly addresses a key challenge faced by edge deployments: maintaining high availability while minimizing infrastructure footprint and cost.
The edge trade-off: availability versus cost
At large scale, hardware cost becomes a critical factor for edge environments. At the same time, many edge sites support mission-critical workloads where downtime is not acceptable. Traditionally, OpenShift control plane high availability relies on an odd number of nodes—typically three or more—to maintain etcd quorum and avoid split-brain scenarios, in line with the CAP theorem.
The two-node OpenShift with arbiter (TNA) architecture resolves this dilemma. Now generally available with OpenShift 4.20, it preserves the consistency and fault tolerance of a three-node cluster while significantly reducing hardware requirements.
How two-node OpenShift with arbiter works
Although it is often described as a two-node solution, this architecture is technically a three-node cluster, purpose-built for cost-sensitive environments:
- Primary nodes: Two full-featured nodes host the OpenShift control plane, run all workloads, and provide core infrastructure services.
- Arbiter node: A lightweight third node runs only the additional etcd instance required to maintain quorum. It does not host applications or standard platform services.
By isolating etcd responsibilities to a minimal third node, the architecture maintains single-node failure tolerance while dramatically lowering the overall bill of materials compared to deploying three full-sized nodes.
The arbiter itself has modest resource requirements—typically 2 vCPUs, 8 GB of memory, and approximately 50 GB of disk storage. Best practice is to place it close to the primary nodes, ideally within the same site but in a separate failure domain. In some scenarios, the arbiter can also be hosted remotely, such as in a central datacenter or cloud location.
Latency and performance considerations
In this context, “end-to-end latency” includes network round-trip time and disk I/O, focusing on worst-case rather than average performance. Because every etcd write must be acknowledged by the arbiter, clusters must be configured with the etcd slow profile. This means overall control plane operations will be slower compared to standard topologies.
If additional services—such as software-defined storage components—are deployed on the arbiter, their resource and latency requirements must be factored into the design.
Platform and installation flexibility
The two-node OpenShift with arbiter topology supports both x86 and Arm architectures on bare-metal systems certified for Red Hat Enterprise Linux 9 and OpenShift. It operates in platform=none or platform=baremetal modes, allowing the arbiter to run as a virtual machine on any hypervisor supported by RHEL, including KVM, Hyper-V, and VMware.
Standard OpenShift installation workflows are fully supported, including UPI, IPI, Agent-based installs, and Assisted Installer.
High availability characteristics of TNA
From a resilience standpoint, TNA behaves similarly to a compact three-node OpenShift cluster. However, it is more sensitive to capacity planning. To avoid performance degradation during a node failure, each primary node should typically run at no more than 50% utilization. In a failover scenario, the surviving node must absorb the full workload of the failed node—significantly more than the 33% redistribution seen in traditional three-node clusters.
Careful sizing and workload planning are therefore essential.
Understanding the arbiter role
The arbiter is a standard OpenShift node running Red Hat CoreOS, kubelet, networking, and related components. What makes it unique is its dedicated arbiter role, which prevents regular workloads and platform services from being scheduled on it. This ensures the node remains focused solely on maintaining etcd quorum and cluster stability.
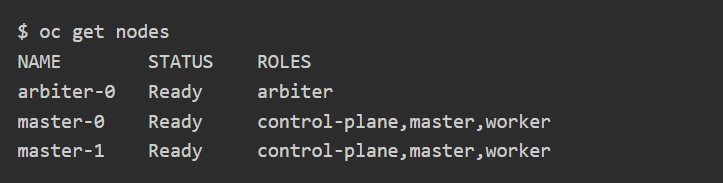
This also means that workloads can be deliberately placed on the node when required by defining an appropriate toleration in the pod or deployment configuration.
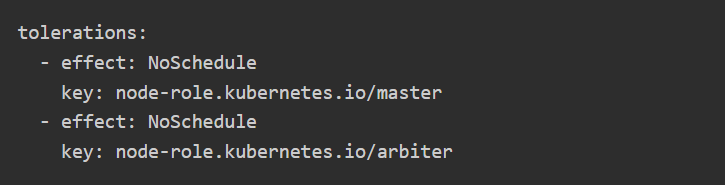
Supporting quorum-based infrastructure services
This capability is particularly valuable for infrastructure services that also depend on an odd number of nodes to establish quorum and maintain consistency. One common example is software-defined, hyperconverged storage, where quorum is essential to ensure data integrity and availability during node failures.
Unified data services purpose-built for the edge
Edge environments—especially those running virtualized workloads—demand more than compute resilience alone. True high availability also requires a reliable software-defined storage (SDS) layer capable of safeguarding data regardless of where applications or virtual machines are executing. This is where Portworx plays a critical role, delivering enterprise-grade data services such as synchronous disaster recovery and automated storage management tailored for distributed edge deployments.
By combining Red Hat OpenShift with OpenShift Virtualization and Portworx, organizations gain a unified platform for managing both containers and virtual machines through a single control plane. This Kubernetes-native, hyperconverged storage architecture brings high availability, strong performance, and built-in disaster recovery to edge locations—without relying on external SANs or dedicated storage appliances.
Advantages of two-node OpenShift with arbiter and Portworx
Deploying two-node OpenShift with arbiter alongside Portworx introduces several key benefits for edge use cases:
Shared quorum architecture
A lightweight arbiter node maintains quorum for both the OpenShift control plane and the Portworx storage control plane. This dual-purpose design ensures platform and storage consistency while keeping infrastructure overhead to a minimum. Portworx requires only modest additional resources—typically 4 vCPUs (x86) and 4 GB of memory per node, including the arbiter.
Built-in data resiliency
Portworx maintains data protection by replicating volumes across the two primary worker nodes using a replication factor of two. This approach ensures persistent storage availability for containerized workloads and virtual machines managed through OpenShift Virtualization, even during node outages.
Advanced data services at the edge
Portworx delivers a comprehensive set of storage and data management capabilities that help organizations:
- Design resilient architectures with zero recovery point objective (RPO) disaster recovery
- Simplify operations through self-service storage provisioning and automated capacity management
- Secure application data with container-level and VM file-based backups, along with ransomware protection
By managing data for containers, virtual machines, and disks in a unified way, Portworx enables edge modernization without forcing organizations to abandon existing virtualized workloads. It also preserves essential Day 0, Day 1, and Day 2 operational capabilities, including synchronous replication, automated scaling, and seamless backup and restore.
Production-ready edge storage support
Portworx version 3.5.0 introduces full support for two-node OpenShift with arbiter as part of OpenShift 4.20. This makes the architecture suitable for production-grade edge deployments that demand both resilience and cost efficiency.
A cost-optimized, resilient foundation for hybrid cloud at the edge
Together, two-node OpenShift with arbiter and Portworx by Pure Storage solve one of the most persistent edge challenges: reducing infrastructure footprint without compromising availability or data protection. This combination enables organizations to run stateful, mission-critical workloads at scale while maintaining consistent storage operations and near-zero RPO for business continuity.
As edge computing continues to evolve, this lean yet resilient architecture provides a future-ready platform for both containerized and virtualized applications across the open hybrid cloud.
To learn more about scaling and protecting stateful workloads at the edge, explore OpenShift edge resources or connect with the Red Hat OpenShift team to learn about the availability and adoption of two-node OpenShift with arbiter.