What is the Aggregation pipeline in MongoDB?
Aggregation operations in MongoDB process the data documents and records and return computed results. It gathers values from numerous documents, groups them, and then applies various operations, including sum, avg, min, and max, to the grouped data to get a computed result. It is comparable to how SQL’s aggregate function works.
There are two methods for doing Aggregation operations:
- An aggregation Pipeline is utilized.
- using techniques for single-purpose aggregation
The single-purpose aggregating methods are listed below.
db.collection.estimatedDocumentCount(), db.collection.count() and db.collection.distinct().
Aggregation Pipelines
The db.aggregate() or db.collection.aggregate() method passes one or more steps, which make up the aggregation pipeline.
db.collection.aggregate([ {stage1}, {stage2}, {stage3}…])
The pipeline of stages on the collected data is processed by the aggregation framework, providing you with the output you require.
Every step receives the results of the stage before it, processes the data further, and then sends the data as input to the stage after. The aggregation process can use the indexes on the server.
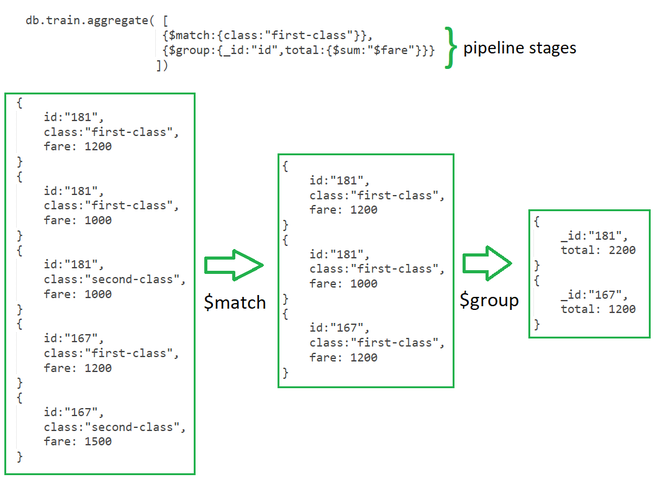
You can understand how pipeline phases function by looking at the image above.
Each stage begins with the stage operators, which are:
$match: It can decrease the number of papers provided as input to the following stage by filtering the documents.
$project: It is used to pick a subset of a collection’s fields.
$group: It is used to classify documents according to value.
$sort: The document that is rearranging them is utilized to sort it.
$skip: It is employed to pass the remaining papers while skipping n of them.
$limit: It is used to limit them by only allowing the first n papers to pass.
$unwind: It deconstructs an array field in the documents to return documents for each element. It is used to unwind documents that employ arrays.
$out: It is used to add new documents to a collection.
Expressions: It makes reference to the field’s name in input documents, for instance. { $group : { _id : “$id“, total:{$sum:”$fare“}}} Here $id and $fare are expressions.
Accumulators:
In the group stage, these are primarily employed as follows:
It adds numerical values for each group’s documents.
Count: It totals the number of documents.
Avg: It determines the mean of all inputted values across all documents.
Min: Out of all the documents, it receives the lowest value.
Max: It maximizes the value of all the documents.
First: It retrieves the grouping’s first document.
Last: From the grouping, it retrieves the most recent document.
Note:
_id is a mandatory field in the $group.
The pipeline’s final stage must be $out.
$sum: will tally the number of papers and the sum:
“$fare” will display the total amount of fare generated for each ID.