

A Smarter Way to Run Multiple AI Models
In this blog, we will learn how to run Multiple AI Models in a Smarter way.
The excitement around Large Language Models (LLMs) is impossible to ignore. From intelligent customer support and document analysis to AI coding assistants and automation workflows, organizations across industries are racing to integrate AI into everyday operations.
But while the possibilities seem endless, there’s a challenge many teams discover only after deployment: running LLMs in production is expensive. And in most cases, the biggest cost isn’t training the model — it’s serving it continuously at scale. As enterprises move from experimentation to real-world adoption, infrastructure efficiency is becoming just as important as model accuracy.
The question is no longer:
“Can we run AI?”
It’s becoming:
“Can we run AI efficiently without wasting GPU resources?”
That’s exactly where projects like kvcached and Sardeenz enter the conversation.
The Hidden Cost of AI: Inference at Scale
Many organizations assume model training consumes the majority of AI budgets. In reality, inference often becomes the long-term financial burden.
Training may happen occasionally, Inference happens continuously. Every user query, generated token, summarized document, or chatbot response consumes GPU resources. Over time, even small inefficiencies become costly:
- Idle GPU memory
- Underutilized hardware
- Cold starts
- Overprovisioned infrastructure
- Dedicated GPUs sitting partially unused
The challenge becomes even larger when organizations deploy multiple models simultaneously.
A business might run:
- A coding assistant
- A customer support chatbot
- A summarization model
- A domain-specific fine-tuned model
Traditionally, each model is assigned its own GPU environment. But most models don’t fully utilize the GPU allocated to them. For example, an 8B parameter model may consume only a fraction of an 80GB GPU’s memory, leaving massive unused capacity behind.
Multiply this inefficiency across teams, environments, and workloads — and infrastructure costs escalate rapidly.
Why Traditional GPU Partitioning Falls Short
The industry has already attempted to improve GPU sharing through technologies like:
- NVIDIA MIG
- Fractional GPUs
- Multi-Process Service (MPS)
These solutions are powerful, but they often rely on relatively static resource allocation.
The Problem?
AI workloads are rarely static.
A coding assistant may experience heavy daytime traffic but remain mostly idle overnight. Meanwhile, batch-processing workloads might spike during off-hours.
Static GPU partitioning struggles to adapt dynamically to changing demand patterns, often leaving performance and cost savings untapped.
Bringing Virtual Memory Concepts to GPUs
This is where kvcached introduces a different way of thinking.
Inspired by how operating systems handle virtual memory for CPUs, kvcached applies similar principles to GPU-based LLM serving. Instead of permanently reserving large chunks of GPU memory for each model, kvcached dynamically allocates memory only when it’s actually needed.
Here’s the key idea:
- Models reserve virtual memory space
- Physical GPU memory gets assigned only during active usage
- Memory is returned to a shared pool when requests finish
This creates a flexible memory-sharing system where multiple models can efficiently coexist on the same GPU infrastructure.
The Result?
Better GPU utilization, reduced waste, and improved performance during bursty workloads.
In benchmark tests involving multiple Llama-3.1-8B models on a single NVIDIA A100 GPU, kvcached reportedly reduced time-to-first-token latency by more than 2x.
That improvement directly translates into:
- Faster responses
- Higher throughput
- Fewer GPUs required
Sardeenz: The Operational Layer for Multi-Model AI
Efficient memory sharing alone doesn’t solve the full production challenge.
Teams still need answers to operational questions like:
- Which models should run where?
- How do we load or unload models dynamically?
- How do applications access different models?
- How do we monitor GPU usage in real time?
That’s the role of Sardeenz.
Built as a management layer on top of technologies like kvcached, Sardeenz provides a centralized platform for operating multiple LLMs across shared GPU resources.
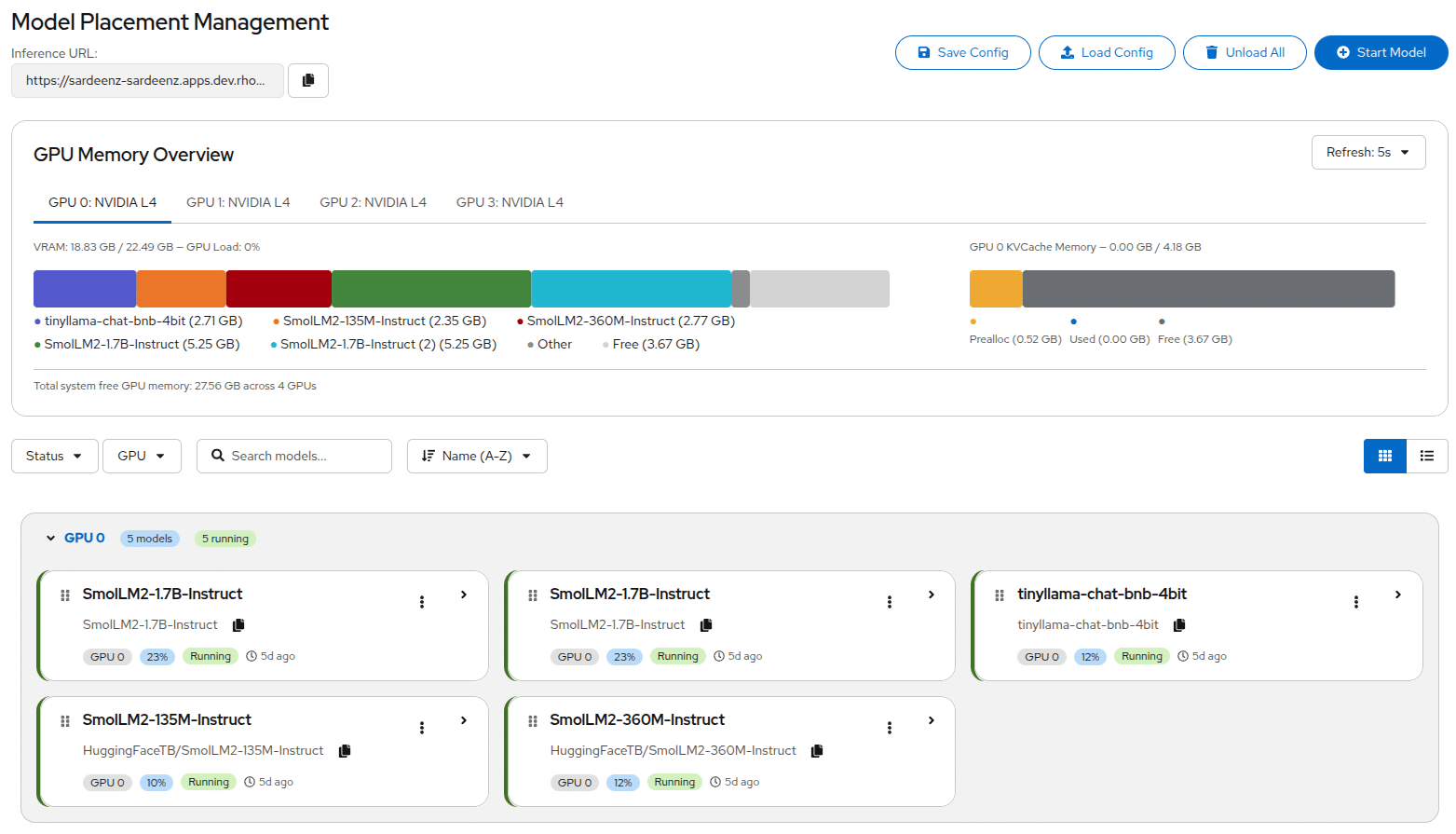
Its capabilities include:
- Dynamic Model Management
Load or unload models without disrupting active workloads.
- Unified API Access
Expose all models through a single OpenAI-compatible endpoint.
- Real-Time Dashboard
Monitor GPU usage, KV cache allocation, and model status visually.
- Benchmarking Tools
Measure latency, throughput, and performance under shared workloads.
- Blue-Green Migration
Move models between GPUs safely without downtime.
- Sleep Mode
Offload inactive models into system RAM instead of fully unloading them, allowing faster recovery when needed.
A Practical Example
Imagine a company running:
- A chatbot for support teams
- A code assistant for developers
- A summarization model for internal documentation
Instead of dedicating separate GPUs to each model, Sardeenz allows them to share infrastructure dynamically.
During work hours:
- Developer workloads get priority
At night:
- Batch summarization tasks consume more GPU capacity
No redeployments.
No manual GPU reconfiguration.
No infrastructure sprawl.
Everything routes through a single endpoint while GPU memory adapts dynamically in the background.
Where This Approach Makes the Most Sense
Projects like kvcached and Sardeenz are especially valuable for:
- Research Labs
Small teams experimenting with multiple models on limited hardware. - Mid-Sized Enterprises
Organizations needing internal AI platforms without massive infrastructure budgets. - On-Premise AI Deployments
Government, healthcare, and financial institutions where cloud-hosted AI isn’t an option. - Development & Testing Environments
Teams needing lightweight multi-model infrastructure for staging and experimentation.
Where It May Not Fit
This architecture isn’t designed to replace hyperscale inference platforms, Organizations running:
- Massive multi-node GPU clusters
- Ultra-low-latency production systems
- Extremely high-throughput workloads
may still require more specialized infrastructure solutions. But for teams managing a moderate number of GPUs and models, this approach can significantly improve utilization while simplifying operations.
The Bigger Shift Happening in AI Infrastructure
What makes projects like kvcached and Sardeenz interesting isn’t just the technology itself.
It’s what they represent.
We’re beginning to see AI infrastructure evolve the same way traditional computing evolved years ago:
- From dedicated hardware
- To virtualization
- To dynamic orchestration
- To shared infrastructure optimization
GPU resources are becoming too valuable to waste on static allocations.
As AI adoption accelerates, smarter resource sharing may become a foundational requirement — not just an optimization.
Final Thoughts
The future of enterprise AI won’t be determined only by which models organizations choose.
It will also depend on how efficiently those models are deployed, shared, managed, and scaled.
kvcached and Sardeenz offer a compelling glimpse into what that future might look like:
- Dynamic GPU memory utilization
- Multi-model infrastructure
- Operational simplicity
- Better hardware efficiency
For teams constrained by GPU budgets but expanding AI ambitions, this approach could unlock significantly more value from existing infrastructure.





