

How to Build research platform that science needs with RedHat AI
In this blog, we will learn How to Build the Future of AI Research: Unifying HPC, Cloud-Native Infrastructure, and AI Services.
Large language models (LLMs) become significantly more valuable when they are customized for specific domains. Fine-tuned models allow organizations to embed institutional knowledge, research expertise, and specialized reasoning into AI systems that can accelerate discovery and support complex decision-making.
However, customized models alone are not enough. To deliver meaningful value at organizational scale, institutions need a platform capable of training, serving, governing, and integrating these models into existing research environments. Such a platform must bridge traditional high-performance computing (HPC) infrastructures, commonly managed through Slurm, with modern cloud-native AI ecosystems built on Kubernetes.
This article explores the architecture that enables research institutions to unify HPC and cloud-native workloads, operationalize customized models as shared services, and provide generative AI capabilities across the organization while maintaining governance, reproducibility, and cost efficiency.
The Platform Architecture
The architecture applies broadly across research-driven organizations, including universities, government laboratories, healthcare institutions, energy companies, and financial services organizations. While implementation details vary by industry, the foundational components remain consistent.
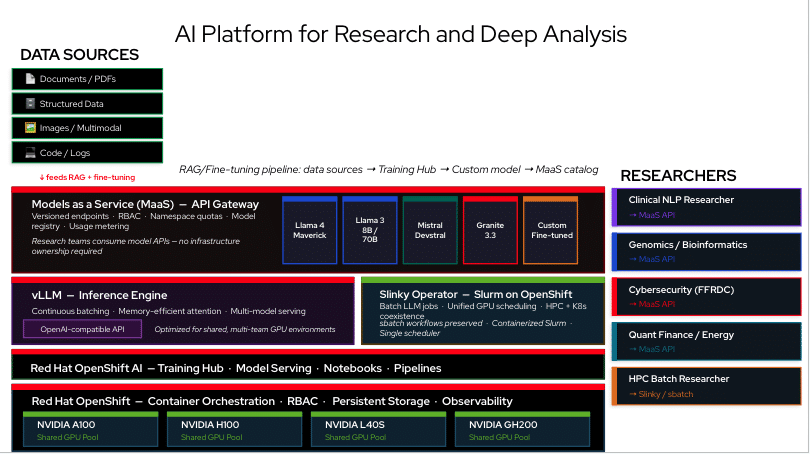
At the core is Red Hat OpenShift, an enterprise Kubernetes platform that provides container orchestration, namespace governance, role-based access control (RBAC), persistent storage integration, and operational management capabilities required to support shared AI infrastructure.
Built on top of OpenShift, Red Hat OpenShift AI introduces AI-specific services such as:
- Model training and customization
- Model serving and deployment
- Pipeline orchestration
- Notebook environments for researchers and data scientists
- Monitoring and observability for AI workloads
These capabilities enable teams to train, fine-tune, evaluate, deploy, and monitor models through a governed self-service environment without managing the underlying machine learning infrastructure themselves.
Efficient Model Serving with vLLM
For model inference, organizations can leverage vLLM through OpenShift AI’s model-serving framework. Its continuous batching and memory-efficient architecture improve GPU utilization, making it particularly effective in shared environments where multiple teams access model endpoints simultaneously.
In research environments where GPU resources are limited and expensive, efficient inference directly impacts operational costs and overall platform scalability.
Accelerating AI Adoption with Red Hat AI Factory and NVIDIA
The Red Hat AI Factory with NVIDIA combines NVIDIA GPU infrastructure and NVIDIA Inference Microservices (NIM) with OpenShift AI’s orchestration, governance, and lifecycle management capabilities.
NVIDIA NIM packages optimized and validated model deployments into containers that are ready to run on NVIDIA hardware. When deployed on OpenShift, these models automatically benefit from platform-level governance, RBAC, monitoring, and operational controls.
For institutions investing in GPU infrastructure, this reference architecture provides a validated path from hardware acquisition to production AI services, significantly reducing deployment complexity and integration effort.
Organizations can start with foundation models available through the NVIDIA NIM catalog and extend them through domain-specific fine-tuning using OpenShift AI customization workflows, enabling use cases such as clinical AI, scientific research assistants, financial analysis, and cybersecurity intelligence systems.
Bridging HPC and Cloud-Native Workloads with the Slinky Operator
Many research organizations rely on Slurm for managing HPC workloads. Slurm remains the standard scheduler for scientific computing because of its mature resource management, GPU scheduling capabilities, and integration with traditional HPC environments.
Historically, HPC and Kubernetes environments have operated independently, creating challenges such as:
- Separate scheduling systems
- Independent resource management processes
- Duplicate operational tooling
- Manual movement of data between environments
- Underutilized GPU resources
The Slinky Operator addresses this challenge by deploying and managing Slurm services as containerized workloads inside OpenShift.
This integration delivers several key benefits:
Unified Resource Utilization
Slurm jobs and Kubernetes-native AI workloads can share the same GPU infrastructure. Idle resources can dynamically support AI training or inference workloads rather than remaining unused.
Familiar User Experience
Researchers continue using familiar Slurm commands such as sbatch without changing established workflows, while platform teams gain the operational benefits of Kubernetes.
Reproducible Research
Containerized Slurm jobs ensure consistent execution environments, improving reproducibility and simplifying collaboration across teams and institutions.
Simplified Operations
Instead of maintaining separate infrastructures, platform teams manage a single environment with unified monitoring, governance, and security controls.
This convergence enables organizations to maximize the value of existing HPC investments while supporting modern AI workloads on the same infrastructure.
Models-as-a-Service (MaaS)
Infrastructure convergence solves only part of the challenge. Most researchers are experts in science, medicine, engineering, or finance—not Kubernetes administration or machine learning operations.
This is where Models-as-a-Service (MaaS) becomes critical.
MaaS allows platform teams to manage AI models as shared organizational services while exposing them through standardized APIs for researchers and application teams.
Traditional Approach
Without MaaS, research groups often spend weeks or months:
- Configuring GPU environments
- Installing software dependencies
- Managing model serving frameworks
- Troubleshooting infrastructure issues
Valuable research time is consumed by operational tasks rather than scientific discovery.
MaaS Approach
With OpenShift AI and MaaS:
- Platform teams manage infrastructure and model operations.
- Researchers focus on datasets, experiments, and domain expertise.
- Fine-tuned models are deployed as governed API endpoints.
- Model versions are tracked and maintained centrally.
- Multiple teams can consume the same model services.
This significantly improves productivity while reducing duplication of effort across the organization.
Governance and Control
MaaS provides operational capabilities including:
- Namespace-level resource quotas
- Model version management
- Role-based access control
- Usage monitoring and observability
- Centralized lifecycle management
These controls allow institutions to scale AI adoption without proportionally increasing operational overhead.
Solving the Data Gravity Challenge
Research organizations generate enormous volumes of data, including:
- Clinical records
- Genomic datasets
- Scientific simulations
- Financial research data
- Industrial telemetry
Moving these datasets to external cloud environments is often impractical due to cost, latency, security, or compliance requirements.
The platform architecture addresses this challenge by bringing AI capabilities directly to where data resides.
Training, fine-tuning, and inference can occur within existing research environments, reducing data movement while improving performance and maintaining governance requirements.
This approach is increasingly becoming an architectural necessity rather than simply an optimization.
Industry Applications
The architecture supports a wide range of research-intensive environments.
Research Universities and National Laboratories
Universities and federally funded research organizations often operate both HPC clusters and growing AI platforms. A unified architecture helps support diverse research communities while maximizing infrastructure utilization.
Healthcare and Medical Research
Healthcare institutions require domain-specific AI models that operate within strict privacy and compliance boundaries. On-premises deployment, auditability, and governance are essential requirements.
Defense and Intelligence
Organizations operating in classified or controlled environments need AI systems that function without dependence on external cloud services while maintaining strict security controls.
Financial Services
Quantitative research, risk analysis, and regulatory compliance workloads require AI systems trained on proprietary data and deployed within governed enterprise environments.
Energy and Industrial Research
Simulation-heavy environments in energy, manufacturing, and industrial research benefit significantly from shared HPC and AI infrastructure, particularly when machine learning workflows depend on outputs generated by large-scale simulations.
What the Platform Enables
A unified research AI platform creates opportunities across the organization.
A computational genomics researcher can run large-scale Slurm jobs on shared GPU infrastructure while seamlessly accessing AI-driven analysis services.
A clinical research team can fine-tune specialized healthcare models and publish them as managed services for other departments.
A cybersecurity research group can deploy AI models trained on sensitive internal datasets without exposing data to external providers.
Meanwhile, platform engineers gain centralized visibility into:
- GPU utilization
- Model-serving performance
- Training workloads
- Resource consumption
- Infrastructure health
All managed through a single operational environment.
Conclusion
As AI becomes a foundational tool for research and innovation, institutions need platforms that allow researchers to focus on discovery rather than infrastructure management.
By combining Red Hat OpenShift, OpenShift AI, NVIDIA technologies, and the Slinky Operator, organizations can build a unified platform that:
- Converges HPC and cloud-native computing
- Supports domain-specific model customization
- Delivers Models-as-a-Service at scale
- Keeps AI close to governed research data
- Maximizes infrastructure utilization
- Simplifies platform operations
The result is a modern AI research platform that enables researchers, data scientists, and platform teams to work together efficiently while accelerating innovation across the organization.





