

An overview of OpenShift Cluster and Machine Autoscaler
Here in this blog, we are going to learn an overview of OpenShift Cluster and Machine Autoscaler. In the scaling-up scenario, the Cluster Autoscaler uses a timer (–scan-interval, default:10s) to periodically check for any un-schedulable pods. When this number rises owing to a lack of resources, it attempts to expand the cluster by adding more nodes.
Following that, MachineAutoScaler automatically scales the MachineSet desired state up and down and sets boundaries for the minimum and maximum number of configured machines, while ClusterAutoScaler determines the scaling up and down depending on numerous factors like CPU, memory, etc. Everything functions without relying on the underlying cloud infrastructure! The operation is depicted in the diagram below.
There is a similar mechanism for the scale-down scenario, where CA may consolidate pods onto fewer nodes to free up and terminate a node. This can be helpful for controlling resources during slow periods of traffic or lowering expenditures. Moving pods can, however, disturb some applications, so this is something to keep in mind. It is crucial to carefully analyze the effects of scale-down before putting it into practice.
Note: For Baremetal to function as a cloud provider, the user must set up BMH for any additional nodes that need to be scaled up. As many additional new nodes as necessary may be added. Later parts contain information on how to create BMH.
Tables with Cluster Autoscalers
Autoscaler Cluster Parameters
Click this Tables of raw Cluster Autoscaler parameters

Click this Tables of raw Cluster Autoscaler parameters

Prerequisites
- Initial OpenShift Infrastructure topology with a 3+2 arrangement
2. OpenShift 4.12.x (this is only an example)
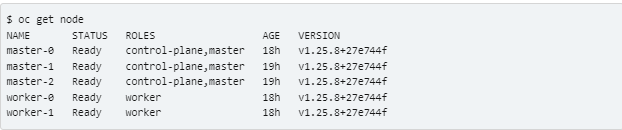
3. An existing machineset for BM is often produced if 3+1+ is used in the deployment.
If not, you must construct machinesets; see this page. assemble a machineset

4. New servers with an IP strategy for building BMH
5. Bare metal servers of the type tested by Dell can be used with HP or other types of hardware servers if the BMC is RedFish or IPMI compatible.
Prepare the Machine Autoscaler and the OpenShift Cluster.
For new node worker-2, create BMH, secret, and NMSTATE
Click for more information about creating BMH. BMH bmh-worker-2.yaml creation:
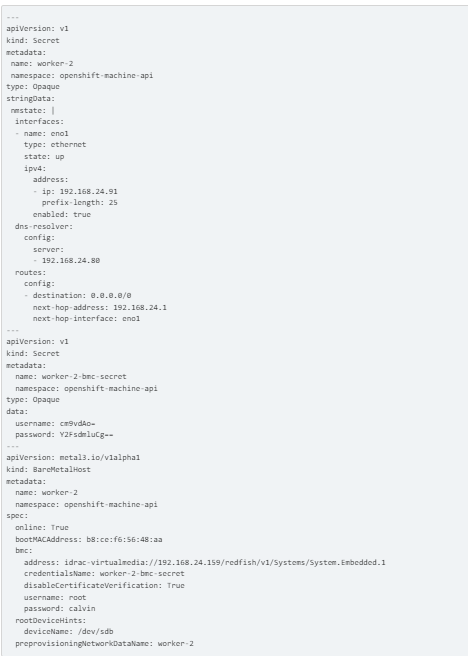
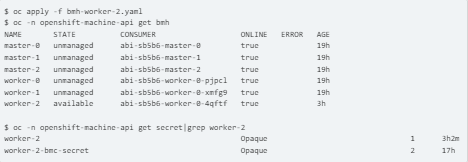
INSTALLING CLUSTER AUTOSCALER
Cluster AutoScaler Definition
cluster-autoscaler.yaml:
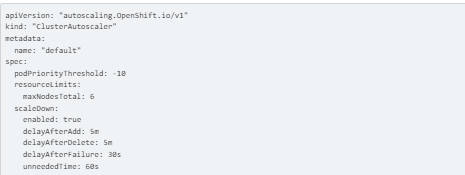
Please click here for more information on each parameter. Autoscaler-Definition
Note: The CPU and Memory are not specified under resourceLimits because we execute cluster autoscaler on BM infrastructure, but maxNodesTotal must be greater than the initial configuration, for example, 3+2 and + worker-2 = 6. There can only be one ClusterAutoscaler per Cluster, and the default name cannot be altered.
Important: Make sure the maxNodesTotal value you define for the ClusterAutoscaler resource definition is large enough to take into account all potential machine numbers in your cluster. This number must include both the number of compute machines you might scale to and the number of control plane machines.
1. Cluster Autoscaler creation
There will be a new pod and cluster-autoscaler-default.

2. Machine-autoscaler.yaml is the definition of a machine autoscaler.
This command can retrieve the MachineSet name:
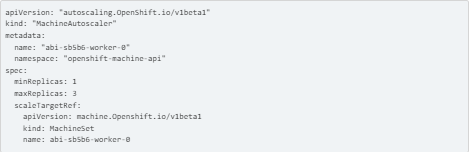
Set the minReplicas and maxReplicas parameters appropriately.
![]()
Note: Minimum is more than 1. Maximum must be in correlation with CA’s maxNodesTotal.
3. Machine Autoscaler Deployment
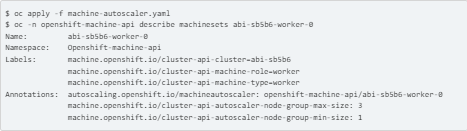
START OPENSHIFT CLUSTER SCALE-UP FOR WORKER-2 NODE
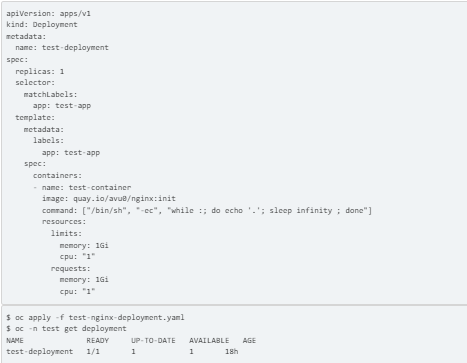
4. Establish a test nginx deployment. POD test-nginx-deployment.yaml:
5. Scale out more nginx PODS to start putting on more CPU/MEMORY load.
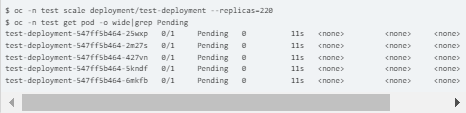
Scale-up log analysis:
After all of the installation is complete, the machineset will automatically update from 2 to 3 before a new machine is built, the BMH of worker-2 is supplied, and the machine for worker-2 is then put into operation.
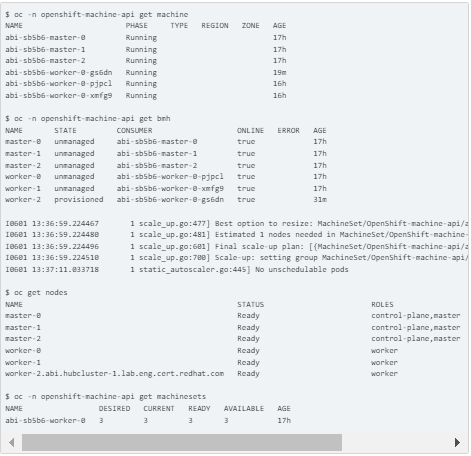
SCALE-DOWN THE OPENSHIFT CLUSTER IN STEPS
- Scale down test-deployment nginx PODS to 100 to reduce traffic volumes.
![]()
Examining scale-down logs and information:

2. Verifying that the machineset value is 2
![]()
3. Status checks for the machine, BMH, and worker-2 node
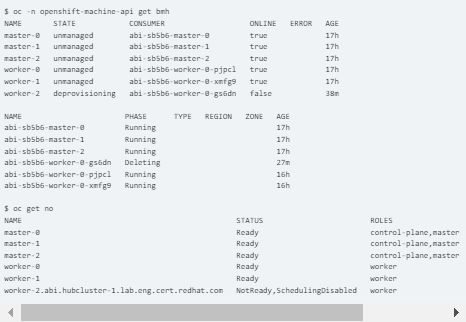
4. Eventually checking after some time and restarting worker 2
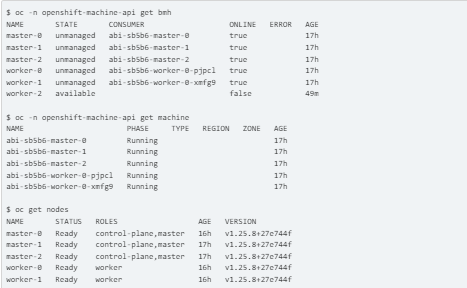
Note: The worker-2 will attempt to deprovision (BMH) and delete (machine) after scaling down. and the worker-2 server will restart, shut down, and turn off.
Diagnostics and Logs Verifying Hints
1. Review the cluster-autoscaler-default logs
![]()
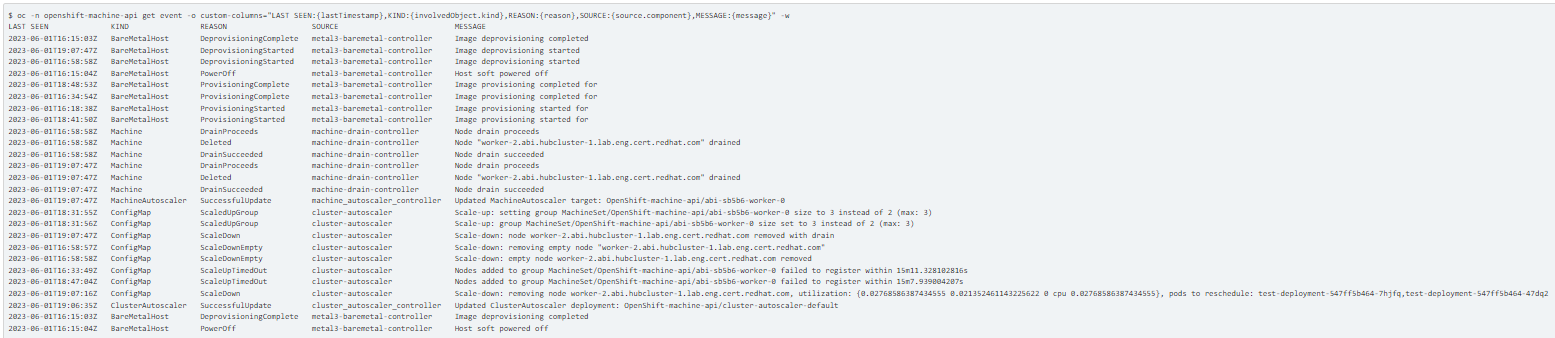
2. Examine the OpenShift-Machine-API Namespace Event Logs for Autoscaler activity.
Links
- FAQ for Cluster Autoscaler
- MAPI and Cluster Autoscaler in OpenShift 4.12
- Operator of the Cluster Autoscaler
- Operator of Machine API
- OpenShift Cluster Autoscaler API.
- Cluster Autoscaler YAML Example
- UML flow for the machine lifecycle
Conclusion
There may be certain disadvantages to using Baremetal as a cloud provider while performing the Cluster and Machine Autoscaler. The precise hardware and software configuration can affect how long it takes to turn on and off Baremetal nodes. It can take several minutes to power on a baremetal node (a few reboots), and up to 8 minutes to power it off and reprovision the BMH node so that it is available and ready for scale up once more, when the Machine Controller initiates the power on/off of the node during scale up or down.
For instance, it can take several minutes for additional nodes to turn on and be prepared to join an existing cluster if an autoscaler is set up to scale up a cluster of Baremetal nodes in response to rising demand. The supply of new services or applications to users may be delayed as a result.





