

BGP learning for Kubernetes nodes
Here in this blog, we will learn about BGP learning Kubernetes nodes.
It’s a common request to have OpenShift (or Kubernetes) cluster nodes capable of BGP route learning.
There are no exceptions to the default route in uncomplicated circumstances when the cluster nodes have a single interface (and default gateway).
The following situations, however, could arise if you have nodes with several interfaces (such as numerous VLANs or bonds or numerous physical interfaces).
Dynamic routing: The network fabric surrounding the cluster is complicated, and some services (such as those of the type LoadBalancer declared by other Kubernetes clusters residing on separate networks) are reachable via multiple interfaces.
Traffic segregation: Due to the need for traffic segregation, many external services can be accessed through various node interfaces. A specific network interface (usually a VLAN corresponding to a VRF in the router) must be used to send traffic to a given CIDR. Static route configuration is just not scalable.
Multiple Gateways: The users are utilizing multiple DCGWs in an active-active configuration to achieve high availability for egress traffic.
Asymmetric return path: Since the nodes lack a route to the client, the return traffic must pass through the default gateway.
The node needs to be aware of the client’s path in order to transmit response traffic to a particular request via the appropriate interface.
Receiving routes with MetalLB
By enabling foreign routers to push routes via BGP to the node’s host networking space, you can fix the issues mentioned above.
MetalLB uses the FRR stack to promote LoadBalancer-type Kubernetes services via BGP.
Although there is an FRR instance running on each cluster node, it can only be used for the very limited MetalLB use case.
Enabling the node routes to be configured by the FRR instance that comes with MetalLB
MetalLB converts the Kubernetes CRD-described configuration to a raw FRR configuration. In addition to the configuration it renders, MetalLB also offers a raw configuration that can be added.
A created rule like prevents the FRR instance running inside MetalLB from allowing incoming routes to be propagated.
![]()
The neighbor’s IP as configured in the BGPPeer instance serves as the name of the rule.
Removing the deny rule with a custom configuration
One line must be added to a ConfigMap for each configured peer in order to allow FRR to receive the routes via BGP. For example:
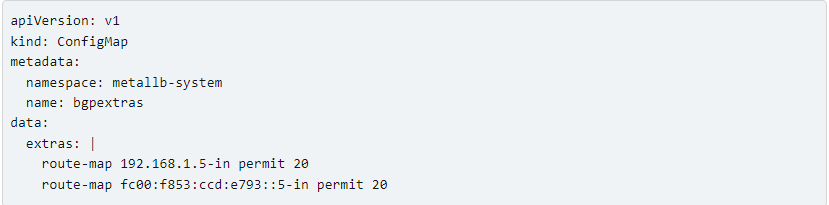
The MetalLB refuse rule will be overridden by this, allowing the FRR instance to receive the routes.
Inbound prefix filtering
The only additional FRR configuration that is permitted is:
- Custom prefix-lists (with a custom name, such as “filtered”) that do not overlap with those produced by MetalLB.
- A route map for each router with the format “route-map xxxx-in permit 20” (using the same 20 index to replace the one MetalLB sets).
- A route map match rule that corresponds to the aforementioned prefix list
Below is an example of the configuration:

Availability
OpenShift 4.12+ and the upstream version of MetalLB (https://metallb.universe.tf) both support this specific configuration. under Tech Preview.
Known problems
The setting must exist before MetalLB creates a session due to the FRR problem. This means that the speaker pods must be restarted if the ConfigMap is produced after the session has already been formed or before the BGPPeer CRDs are. 4.14, which makes use of a more recent version of FRR, does not contain the problem.
Next steps
Where dynamic route learning for the cluster’s nodes is necessary, this initial solution enables you to unlock users. Receiving routes is not actually MetalLB’s goal. However, running numerous FRR instances on the same node presents additional difficulties and wastes resources.
We are redesigning MetalLB as a result, and FRR will now run as a distinct instance with its own API that may be contributed by MetalLB, the user, or other controllers.
The ideal strategy to maximize both node and router resources is to have a single FRR instance on each node because different configurations can share a single BGP/BFD session.
The upstream design proposal is currently under development and is available here for additional information.





