

How to Optimize On-Premises OpenShift 4 IPI with Integrated Load Balancer
A load balancer has been required for the API and ingress services from the first OpenShift 3.x versions. From the perspective of the clients, this allows the cluster nodes to scale up, down, and recover from failure in a transparent (or almost transparent) manner. A load balancer is required for OpenShift 4 to offer a shared, highly accessible endpoint for client access. The user provisioned (UPI), installer provisioned (IPI), and non-integrated installation experiences in OpenShift 4 impose distinct requirements on the administrator for configuring the load balancers, depending on the installation type and infrastructure platform.
When installing IPI on a hyperscaler, the load balancer service of the provider is installed and configured using the installer, then maintained by an operator. But what about on-premises IPI, when a common and predictable API-enabled load balancer service isn’t available? For the same reasons, on-premises IPI clusters require a load balancer, so how is this requirement met?
To begin, consider the load balancer needs for OpenShift clusters.
Endpoints with a Load Balance
The initial step is to recognize that load balancing is required for two principal endpoints: API (api.clustername.domainname) and ingress (*.apps.clustername.domainname). The control plane nodes serve the API endpoint on port 6443. It’s where internal and external clients, such as the oc CLI, connect to the cluster to issue commands and interact with the control plane in other ways.
Ingress is the second load balanced endpoint. This is supported by the ingress controllers, which are often a group of HAproxy pods housed on compute nodes, but it is also one of the “infrastructure” qualified workloads. This is where traffic from ports 80 and 443 is routed into the cluster for external access to hosted applications.
Finally, there’s the “api-int.clustername.domainname” internal API endpoint. The compute nodes utilize this to communicate with the OpenShift control plane. Port 22623, which is used to serve machine configuration to the nodes, is the most well-known and well-known use of this endpoint.
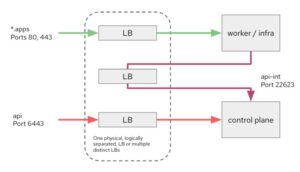
A single load balancer or many load balancers can serve these three endpoints. Because the machine configuration files may include sensitive data, the API-int endpoint can and should have controlled access so that only cluster nodes can access it. If you have numerous ingress controllers for additional domain names or if you’re using sharding, each of them will need a load balancer to send traffic to each of the ingress controller instances, which can be shared or independent.
These prerequisites apply to all OpenShift 4 clusters, regardless of deployment model (IPI, UPI, or non-integrated) or infrastructure platform (AWS, Azure, vSphere, OpenStack, and others). On-premises IPI implementations, including as vSphere and RHV, OpenStack (when not employing Octavia), bare metal IPI, and clusters deployed using the Assisted Installer, all use virtual IPs (VIP) controlled by keepalived to provide “load balancing” for the endpoints.
“Load Balancing” is still alive and well.
Keepalived is a service that allows you to manage virtual IP numbers across several servers. In a nutshell, the participating nodes communicate with one another to determine which node will host the virtual IP address. The IP is subsequently configured on that node, and all traffic is directed to it. If that node is taken offline for whatever reason, such as a reboot or a failure, the nodes elect a new VIP host, who configures the IP address and restores network traffic.
There are two keepalived managed VIPs utilized for on-premises IPI installations with OpenShift 4 IPI clusters: ingress (*.apps) and API. The internal API endpoint (api-int) is handled in a separate way and does not require a VIP. Please bear in mind that this is not the same as the keepalived operator. MachineConfig is used to deploy and configure it at the host level. Other domains, programs, or IP addresses are not customizable.
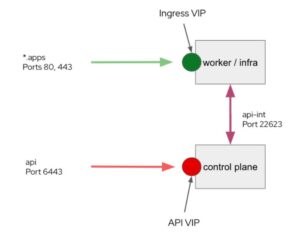
This eliminates the need for the administrator to configure and provision an external load balancer before installing the OpenShift cluster. Instead, they only need to assign the two IP addresses and DNS names that the installer has provided. Keepalived controls the VIPs after they’ve been deployed, making sure the ingress VIP is always running on a control plane node and the ingress VIP is running on a compute node containing an ingress controller pod.
There are, however, some limitations:
- First, you’ll observe that all ingress traffic is funneled into a single node. This could be a bottleneck if you have a significant number of traffic. It’s worth noting that using HAproxy, or a comparable load balancer, deployed to a virtual machine, is a frequent deployment technique with OpenShift, and it has the same (possible) restrictions.
- Increased ingress throughput does not result from increasing the number of ingress controllers. Instead, because the ingress VIP will only be hosted on a node with an ingress controller pod, the VIP’s failover opportunities will be increased.
- Adding extra domains to the OpenShift ingress controller can have unforeseen consequences. Let’s imagine you want to construct a new IngressController with a different domain. This will result in the second set of ingress pods being deployed to the computing nodes, listening on ports 80 and 443 as well. Because the keepalived logic is insufficient to establish which ingress pods are accountable for which domain, the *.apps VIP could end up on a compute node with a *.newdomain ingress pod. Any applications that use *.apps would be unable to ingress as a result of this. Route sharding is ineffective for the same reason.
- All nodes, including the control plane and compute, must be in the same broadcast domain for VRRP to work properly. This practically means that all nodes must be on the same subnet, preventing systems in which the control plane nodes are on a separate subnet or infrastructure nodes are in a DMZ, for example.
- The Virtual Router Redundancy Protocol (VRRP) is used by Keepalived to identify nodes that are participating and eligible to host a VIP. To avoid conflicts when they are in the same broadcast domain, each VRRP domain representing a single VIP in the OpenShift cluster must have a unique ID. During the installation process, the domain IDs for API and ingress are generated automatically from the cluster name. The domain ID is an 8-bit integer, however, the values can only be whole numbers between 1 and 239 due to the way it is created. Because each OpenShift cluster has two domain IDs, collisions are more likely.
- There is currently no method for a new cluster to communicate with existing clusters and resolve VRRP domain ID conflicts. In the event of a dispute, the administrator must identify the domain ID and alter the cluster name. This may be accomplished with podman with the following command:


- Keepalived takes a different amount of time to detect node failure and re-home the VIP, but it is always more than zero. This could be a problem for apps that can’t stand being interrupted for a few seconds.

Keepalived Alternatives for Ingress
It is supported to “transfer” the DNS entries from the VIPs to an external load balancer as a day two-plus operation for particular infrastructure types, specifically OpenStack and bare metal IPI. This effectively replicates the settings of a user-provisioned infrastructure (UPI) deployment type. Unfortunately, not all on-premises IPI infrastructure suppliers, most notably VMware vSphere, support this at this moment.
Another option is to utilize an apps domain, which is documented here for AWS but works with all installations. This causes the cluster to use the configured domain for all routes, but it does not delete or uninstall the keepalived VIPs for the default *.apps domain, so you can’t use *.apps.cluster name.domainname for the appsDomain. The DNS for the appsDomain domain can be pointed to an external load balancer, which is configured similarly to UPI. One potentially significant benefit of this technique is that your application’s DNS names are now detached from the cluster name, making migration between clusters for clients/users much easier.
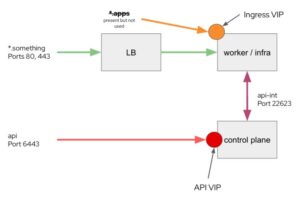
What about MetalLB, which is available with OpenShift 4.9 and later?
MetalLB provides a means for OpenShift applications to request a Service of the type LoadBalancer, which was provided with support for layer 2 mode in OpenShift 4.9 and layer 3/BGP mode in OpenShift 4.10. This is important if you wish to expose applications to clients on ports other than 80 and 443. This may be a MariaDB database that uses port 3306 or an application that spans OpenShift and external resources and communicates via custom ports.
MetalLB cannot be used to replace either the ingress or API endpoints, despite being a very useful and powerful functionality. MetalLB is an after-cluster-deployment feature that isn’t ready in time for the API, which must be available before other features and functions are deployed and configured, or the default ingress domain. The ingress controller(s) and route mechanisms are not coupled with service in this way for ingress (*.apps). It is possible to expose the application using MetalLB and a LoadBalancer Service, and then configure DNS to point to the Service’s assigned IP address; however, this does not provide the benefits of a route, such as automatically integrating certificates and other security features for communications between clients and the server.
Selecting the Best Option
The keepalived solution, which is available as part of on-premises IPI clusters and with Assisted Installer provided clusters, is adequate in many circumstances but, obviously, not in others. When utilizing IPI to deploy clusters, the process must be opinionated: it must be predictable when the installer does not have direct control or configuration of the resource, which limits the alternatives accessible to us today. Although the preceding sections cover possible options, such as using an appsDomain or MetalLB, a traditional load balancer is occasionally required with an OpenShift implementation. If you need a typical load balancer for your cluster, the UPI deployment technique is the best option.
When you choose the UPI approach to deploy a cluster, you’ll have the most freedom during cluster instantiation, allowing you to use the resources that are best for your infrastructure and requirements. You can continue using capabilities generally associated with IPI deployments on day two and later for most infrastructure types (the exception being RHV UPI and non-integrated deployments). MachineSets can be used to (auto)scale cluster compute nodes, for example, because the cloud provider and Machine API components are configured with UPI deployments.
If you want to learn more about OpenShift load balancer settings, capabilities, and limits, check out episodes 60 (MetalLB L3/BGP), 49 (MetalLB L2), and 27 of the Ask an OpenShift Admin live stream (day 2 ops). If you have any questions, please join us on YouTube and Twitch every Wednesday at 11 a.m. Eastern Time to ask them to live, or contact us via social media: @practicalAndrew on Twitter and Reddit.





