

OpenShift introduces disaster recovery across regions
Disaster recovery (DR) is the subject of this blog. In the Kubernetes community, disaster recovery (DR) is becoming more and more of an operational concern as the platform supports stateful applications instead of the mostly stateless ones that are typically deployed today. Maintaining operations in the event of a datacenter, availability zone, or regional outage is the ultimate objective. That implies the continuance of business.
OpenShift is now extending its disaster recovery solutions with the launch of the Regional-DR solution in order to meet that objective. It is based on two OpenShift products: Red Hat OpenShift Data Foundation (RHODF) for persistent data storage and Red Hat Advanced Cluster Management (RHACM) for cluster management.
Recovery from Regional Disasters
Your applications are shielded by the Regional-DR solution from a variety of catastrophic events, including datacenter failures, and large blast radius failures. It is Red Hat OpenShift’s most adaptable and unrestrictive disaster recovery solution. This method is based on two independent clusters at two datacenters that are separated by distance. A reliable DR solution is provided since failures in one cluster or datacenter do not spread to the other cluster.
There are no network constraints or latency limits to implement, and application performance is unaffected by the asynchronous nature of the data replication. It is available on all on-premises and public cloud platforms supported by RHODF and OpenShift. Application-granular DR protection means that DR actions, such as failover and failback, are only performed on the designated applications and do not affect the other applications in the cluster.
Recovery point objective (RPO) and recovery time objective (RTO) are the two main metrics that control disaster recovery solutions. The former measures the maximum amount of data loss an application can withstand in the event of a disaster, while the latter quantifies the maximum amount of downtime the application can afford.
In two data centers connected by a WAN, cluster pairs are deployed using this configuration. These cluster pairs can replicate data asynchronously from volume to volume between them thanks to RHODF, which supplies the persistent data volumes (PVs). RHACM offers automated DR operations for simple recovery. It also handles application placement in the clusters and cluster management.
DR orchestration based on data policies
The RHACM GUI’s data policy framework makes DR orchestration easier. Users can select a schedule interval for the frequency at which the data volume(s) of the application are replicated between the designated primary and secondary cluster pairs using these data policies. The application’s RPO is determined by this schedule interval.
Red Hat OpenShift DR Operators configure the appropriate volume(s) of the application for replication and start the data replication on time, based on the selected data policy. OpenShift DR operators replicate not only the PV data but also the associated PV metadata. RHODF provides and maintains an object store at the secondary cluster where the replicated metadata is kept safe. In the event of a disaster, this metadata is essential for volume failover and application restoration.
Although the number of times the PVs can be replicated across clusters is not limited by RHODF, replication schedule intervals in practice typically range from five to fifteen minutes. Anything less could result in excessive use of network and hardware resources.
Automation of DR based on operators
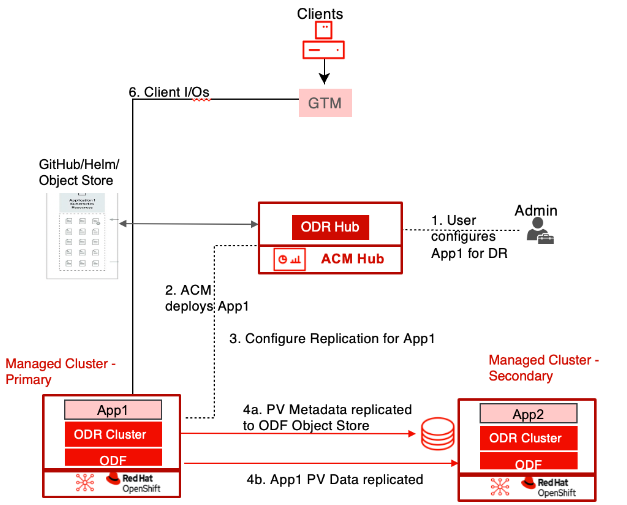
RHACM and RHODF are given to a group of OpenShift DR operators, who handle the application failover while RHODF handles data volume replication. These come in three varieties:
- Installed on the RHACM hub cluster, a central OpenShift DR (ODR) Hub Operator controls application failover and relocation.
- Installed on every managed cluster, an OpenShift DR (ODR) Cluster Operator oversees the protected PVC lifecycle for a given application.
- On the RHACM hub cluster, a RHODF Multicluster Orchestrator is installed to automate various DR configuration tasks.
By reducing the number of actions needed for application recovery to a single user-initiated action, these DR Operators allow applications to failover or relocate between clusters with ease. This method improves recovery time (RTO) by reducing user errors during chaotic disasters and ensuring that applications are recovered consistently and swiftly.
An operational RHACM hub is necessary for DR functions. This requirement means that in the event that a RHACM hub fails, there is a recovery solution for that hub.
DR failover and failback that is automated
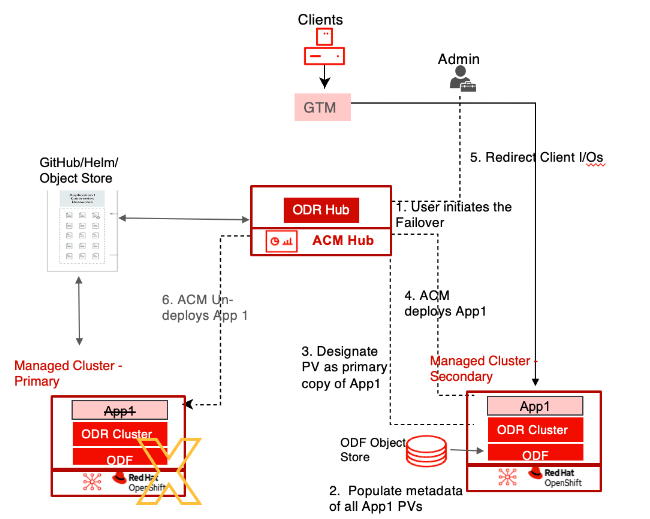
The series of steps necessary for applications to recover on the secondary cluster are automated by ODR operators. When a failure is detected, the user only needs to take one action to initiate the complete failover sequence.
RHACM is a component of the failover operation. It uninstalls the application from the failed cluster, destroys the replication connections between the application’s volumes, mounts the volumes on the DR cluster, populates the application PVs’ metadata on the DR cluster, and installs the application from the Git repository on the secondary DR cluster. Users can control the sequence in which this application-granular failover process is repeated for each application by determining its dependencies and priorities. Because failovers are always controlled and initiated by the user, there are never any unintentional failovers or potential data loss.
Not every application failover is predicated on unavoidable malfunctions that could result in data loss. If an anomaly is found in the application or cluster, or if users notice a decline in the cluster status, they can start a controlled application relocation process without losing any data. The DR operators’ automation has made this process simpler and only requires one click.
A seamless recovery to the primary cluster is made possible by DR failback. Data loss is prevented through the planning, management, and activation of DR failbacks. The RHODF Operators resync the data from the DR cluster back to the primary cluster after the user starts the failback operation. The application failback sequence doesn’t start until the PV data and metadata changes are restored to the primary cluster. After that, the RHACM redeploys the application to the primary cluster and removes it from the DR cluster. The same procedure can be used by administrators to move workloads between private and public cloud environments.
Many modern applications support declarative models, which are the model for which the Regional-DR solution is intended for applications that are deployed. Applications in the declarative model adhere to a declared state that is deployed in the cluster by DevOps tools from a central repository for Git, serving as the only source of truth for the configuration of the application. With these DevOps tools, ODR Operators can steer the application redeployment to a healthy cluster during a DR event.
Conclude
In conclusion, by reducing RPO through RHODF-based ongoing volume replication and RTO through RHACM-based DR Operator controlled automation, the Regional-DR solution improves application protection. By maintaining all clusters operational during the sunny state, it also lowers DR costs by improving resource utilization. Both clusters can be active at the same time, running separate sets of applications and safeguarding one another through cross replication, even though an application instance can only be running at one cluster at a time. One solution that helps safeguard all stateful workloads implemented on OpenShift is regional disaster recovery. DR protection is a crucial component of cluster and application management because of its design and integration with OpenShift cluster tools like alerting and monitoring.





