

Reliable Kubernetes workloads on Red Hat OpenShift with YugabyteDB
Kubernetes has ended up broadly followed withinside the Fortune 500. Many corporations are actually the usage of the platform to run stateless and stateful packages on-premises or as hybrid cloud deployments in production. Of course, with any new technology, there are developing pains whilst walking workloads on Kubernetes with YugabyteDB. But maximum executives and builders agree that the blessings of some distance outweigh the challenges.
On the turn side, information at the Kubernetes atmosphere is evolving swiftly with the upward push of stateful packages. However, stateful packages call for a brand new database structure that takes into consideration the scale, latency, availability, and safety desires of packages. But how do you realize which database structure is exceptionally ready to deal with those challenges?
YugabyteDB: Distributed SQL for Resilient Kubernetes Workloads
YugabyteDB is a cloud-local, disbursed SQL database for transactional applications. The database is 100% open supply and constructed to resolve availability and resiliency demanding situations while strolling software workloads on Kubernetes.
This database features an unmarried logical database deployed as a cluster of nodes. This way the database cluster looks after sharding, replication, load balancing, and records distribution. Therefore, YugabyteDB continues your database up and strolling although there’s a pod, node, or underlying infrastructure failure. The database cluster is capable of locating the failure, managing it, and getting better with no lack of records or get entry to via way of means of the software.
YugabyteDB additionally affords scalable and resilient records save for connecting applications. It looks after migrating records among pods after a pod movement to a brand new node. It does this backstage with no shape of operator intervention.
“Run Anywhere” Distributed Stateful Workloads
YugabyteDB is to be had on Red Hat OpenShift, the industry’s main company Kubernetes platform for deploying and coping with cloud local applications. This way improvement groups can install YugabyteDB on Red Hat OpenShift with confidence. As a result, each is well-included to run on Kubernetes and permits green Day 1-2 operations.
One foremost gain to strolling YugabyteDB on Red Hat OpenShift is geo-disbursed stateful workloads. The following diagram depicts what such a structure looks as if in practice.
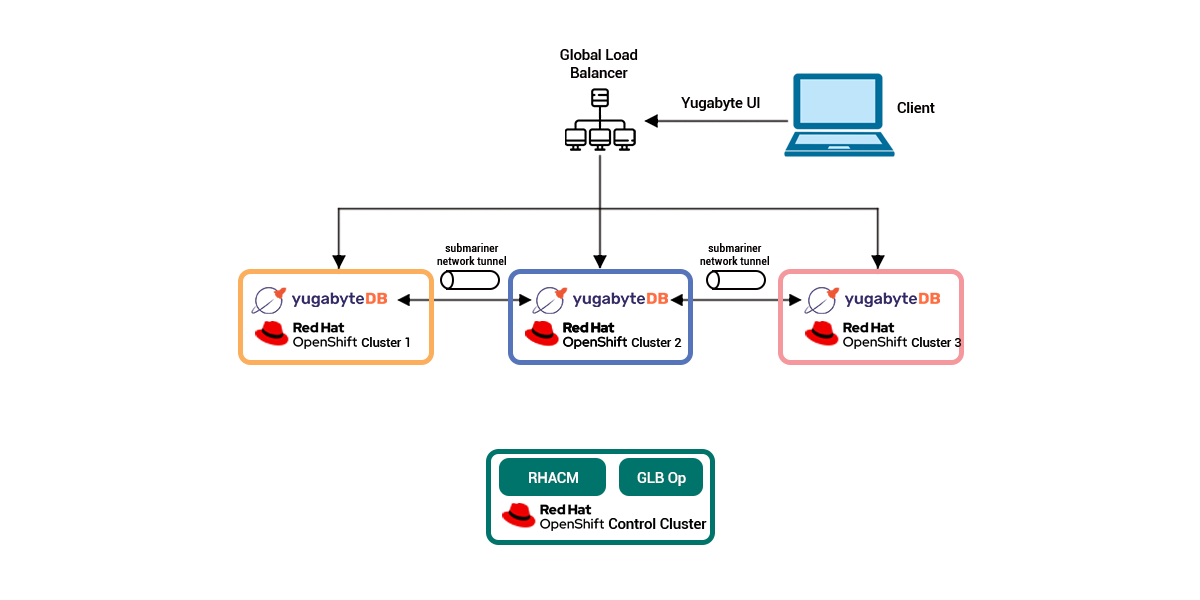
Starting from the pinnacle, we’ve got an international load balancer directing connections to the YugabyteDB UI. Then, there are 3 Red Hat OpenShift clusters with YugabyteDB times deployed to every cluster. These times can talk with every different through a community tunnel carried out with Submariner.
Finally, at the lowest of the diagram, the Red Hat Advanced Cluster Manager for Kubernetes has been mounted inside a manipulated cluster. This is used to create the opposite clusters in conjunction with the worldwide load balancer operator, which enables configuring the worldwide load balancer on the pinnacle of the diagram.
Each cluster is in a distinct location of a public cloud provider.
Zooming in at the YugabyteDB deployment, we’ve got 3 pill servers and a master (metadata server) in every cluster. Together, they shape a logical YugabyteDB instance.
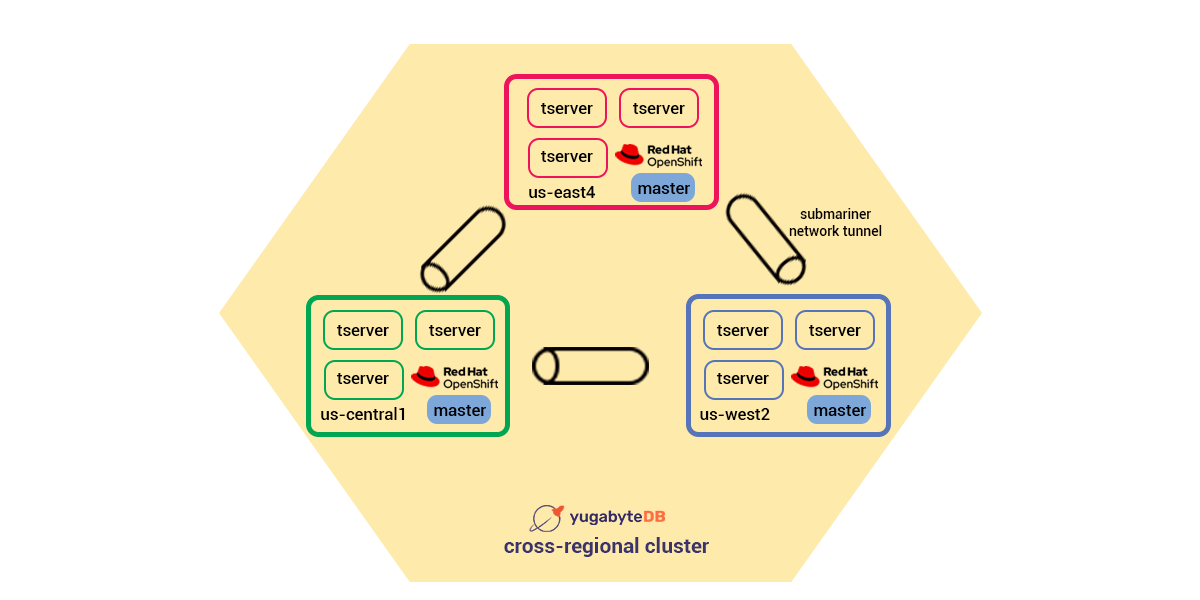
Load check consequences screen this sort of deployment is usable in production, as is proven with the aid of using the mixing paintings accomplished among Yugabyte and Red Hat on this Geographically Distributed Stateful documentation.
Zero Data Loss and Continuous Availability
Another gain to jogging YugabyteDB on OpenShift is 0 information loss and non-stop availability in the course of a primary device outage or herbal disaster. For example, withinside the following diagram, the community of 1 location is remoted with the aid of using stopping any inbound or outbound visitors whilst jogging a TPC-C check.
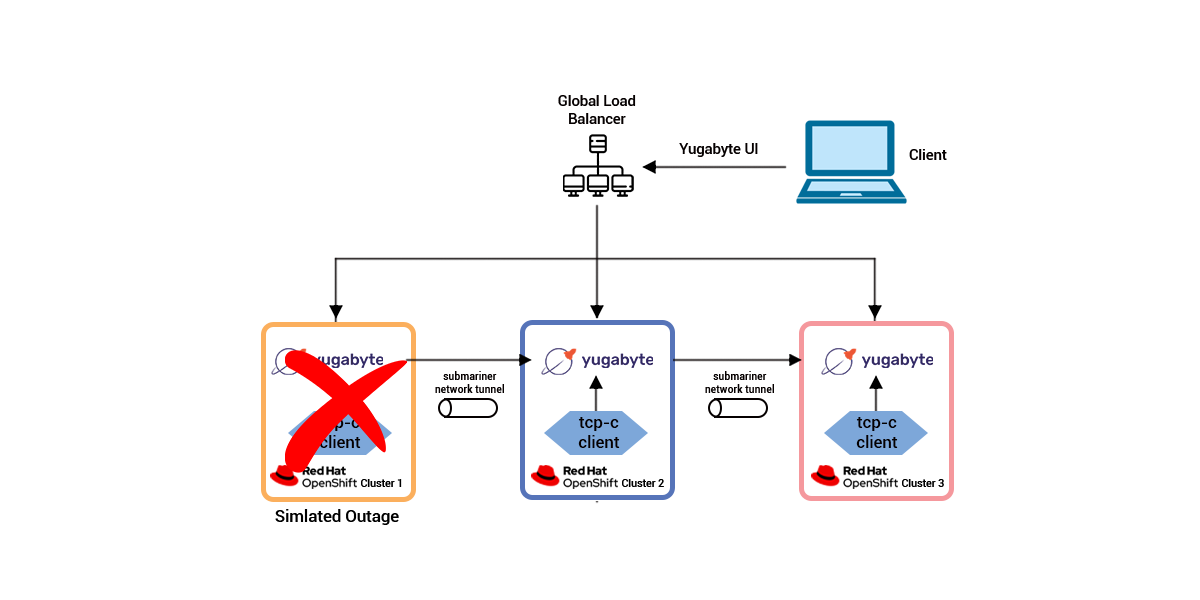
When simulating this catastrophe, there have been some mistakes withinside the surviving TPC-C clients; essentially, a few in-flight transactions have been rejected or didn’t completed. But YugabyteDB moved all the pill leaders to the wholesome instances.
The machine controlled the catastrophe without the want of any human intervention.
When connectivity to the remoted place becomes restored, there have been no troubles withinside the ongoing TPC-C clients. YugabyteDB rebalanced the database via way of means of transferring the pill leaders’ lower back to the newly-to-be pill servers. Again, no human intervention become needed.
During this simulation, the machine skilled 0 statistics loss (RPO 0) and little or no unavailability (RTO measured in seconds).
The Future Is Stateful
Kubernetes has been a paradigm shift withinside the manner organizations construct and install packages to cater to the wishes of a more and more cloud local world. There isn’t any one-size-fits-all database reference structure that works for all packages in this environment. Depending on the necessities of the software and tradeoffs involved, organizations will pick out one-of-a-kind topologies to fulfill their wishes, and alternate the topologies whilst wishes alternate.
YugabyteDB on Red Hat OpenShift gives a effective and flexible statistics layer for going for walks packages in each cloud and Kubernetes environment. This aggregate serves commercial enterprise-crucial packages with SQL question flexibility, excessive overall performance, and cloud-local agility. As a result, YugabyteDB on Red Hat OpenShift lets organizations to attention commercial enterprise boom in place of complicated statistics infrastructure management.





